Erlang 与其他所有编程语言之间最大的区别不在于其并发性,而在于其容错性。该语言中几乎所有内容都是为了容错而设计的,而监管器是这种设计核心部分之一。在本章中,我们将介绍监管树的基础知识,监管器包含的内容以及如何在自己的系统中构建监管树。完成后,您将能够设置和管理系统所需的大部分状态。
基础知识
Erlang 是一种双层语言。在最低层,您有一个函数式子集。您所能获得的只是一堆数据结构、函数和模式匹配来修改和转换它们。数据是不可变的、局部的,并且副作用非常有限,如果不是不必要的话。在较高层,您有并发子集,其中管理着长期存在的状态,并且状态在进程之间进行通信。
函数式子集相当简单易学,可以使用本书简介中提到的任何资源:您获得一个数据结构,对其进行更改,然后返回一个新的数据结构。所有程序转换都作为应用于数据片段以获得新数据片段的函数管道来处理。这是一个可靠的构建基础。
函数式语言的挑战在于如何处理副作用。例如,您将如何获取程序配置并将其传递到整个堆栈中?它将存储和修改在哪里?您如何获取本质上是可变的和有状态的(例如网络流)并将它嵌入到不可变和无状态的应用程序中?
在大多数编程语言中,所有这些都是以一种相当非正式和临时的方式完成的。例如,在面向对象语言中,我们倾向于根据其域的边界来选择副作用的位置,同时可能尝试遵循诸如持久性忽略或六边形架构等原则。
最终,您可能最终得到一种分层系统,其中您希望在核心部分有一堆纯域特定实体,在外部边缘有一堆交互机制,以及一些中间层,其作用是在实体之间协调和包装所有活动。
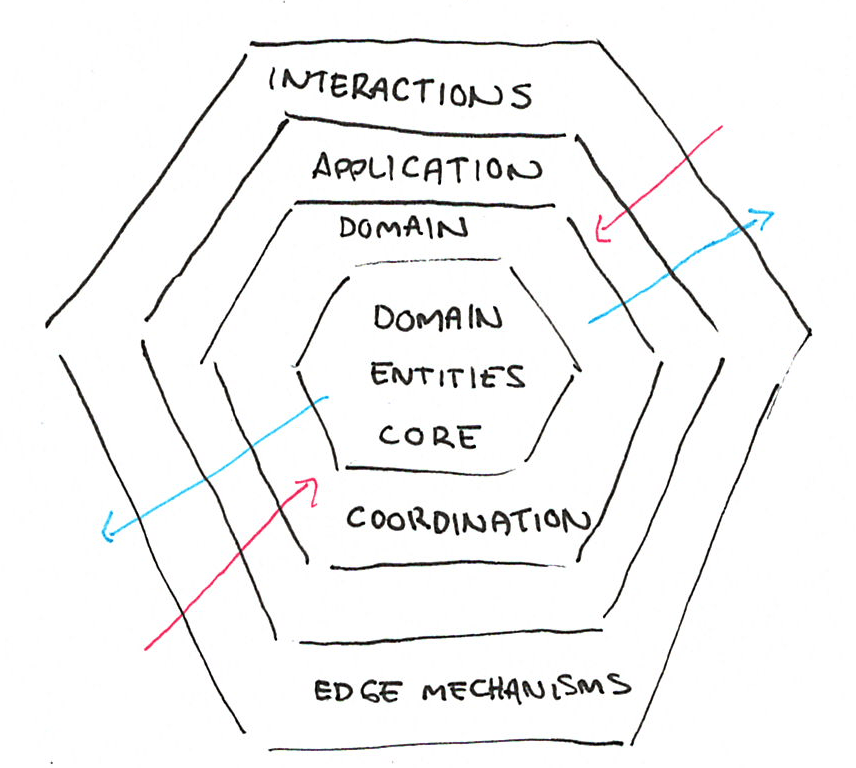
图 1:面向对象设计中经常推荐的六边形架构
这种结构通常在域建模方面非常明确,但在交互和副作用的结构方面却相当模糊。联系外部服务的失败应该如何冒泡?当核心域实体上的转换无法保存时,来自某些事件驱动机制的外部边缘交互会受到什么影响?
您在面向对象系统中进行的域建模仍然可以在 Erlang 中进行。我们将所有这些内容放在语言的函数式子集中,通常放在一个库应用程序中,该应用程序重新组合执行所需更改和转换的所有相关模块,或者在某些情况下放在可运行应用程序的特定模块中。
但是,故障和故障处理的丰富性将在监管结构中明确编码。因为系统的有状态部分是使用进程编码的,所以依赖关系的结构及其各自的实例化都一目了然。
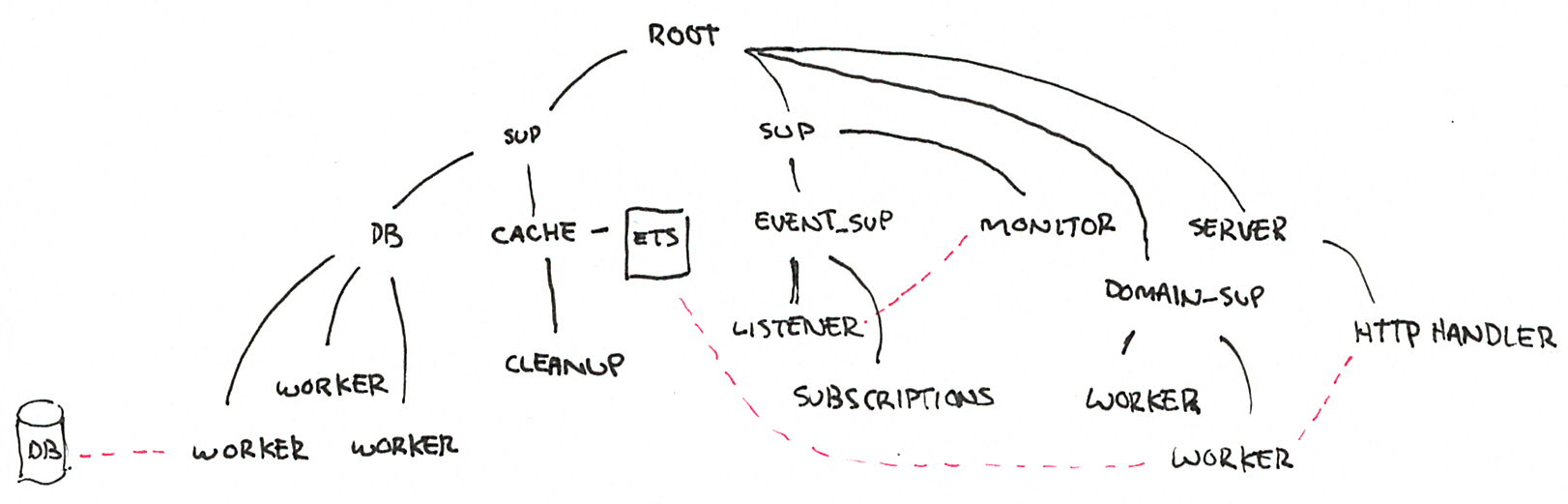
图 2:监管树示例
在这样的树中,所有进程都是深度优先、从左到右启动的。这意味着在启动缓存进程和ETS 表之前,必须首先启动数据库的监管结构(及其所有工作进程)。类似地,在启动 HTTP 服务器及其处理程序之前,必须先创建整个业务域子树,并且由于它依赖于缓存表,因此我们同样会确保此表(和数据库工作进程)已准备好运行。
此监管结构定义了发布如何启动,但也定义了它如何关闭:深度优先,从右到左。而且,每个监管器都可以设置其自己的策略和对子进程故障的容忍度。这意味着它们还定义了系统中允许或不允许哪种部分故障。如果节点无法与数据库通信,它是否仍应运行?也许它应该运行,但如果缓存不可用,它就不能保持运行。
简而言之,在可以使用函数式内容进行特定于域的处理的地方,状态组件对状态、事件以及与外部世界的交互的流程进行了编码和明确说明,从而为我们提供了一种处理错误和初始化的全新方法。
我们稍后将了解如何做到这一点,但首先,让我们回顾一下监管器的工作原理。
监管器包含什么
从表面上看,监管器是所有 Erlang/OTP 中最简单的行为之一。它们接受单个 init/1 回调,仅此而已。回调用于定义每个监管器的子进程,并配置其对各种故障做出反应的一些基本策略。
有 3 种策略需要处理
- 监管器类型
- 子进程的重启策略
- 可接受的故障频率
每种策略在孤立状态下都足够简单,但选择合适的策略可能会有点棘手。让我们从监管器类型开始
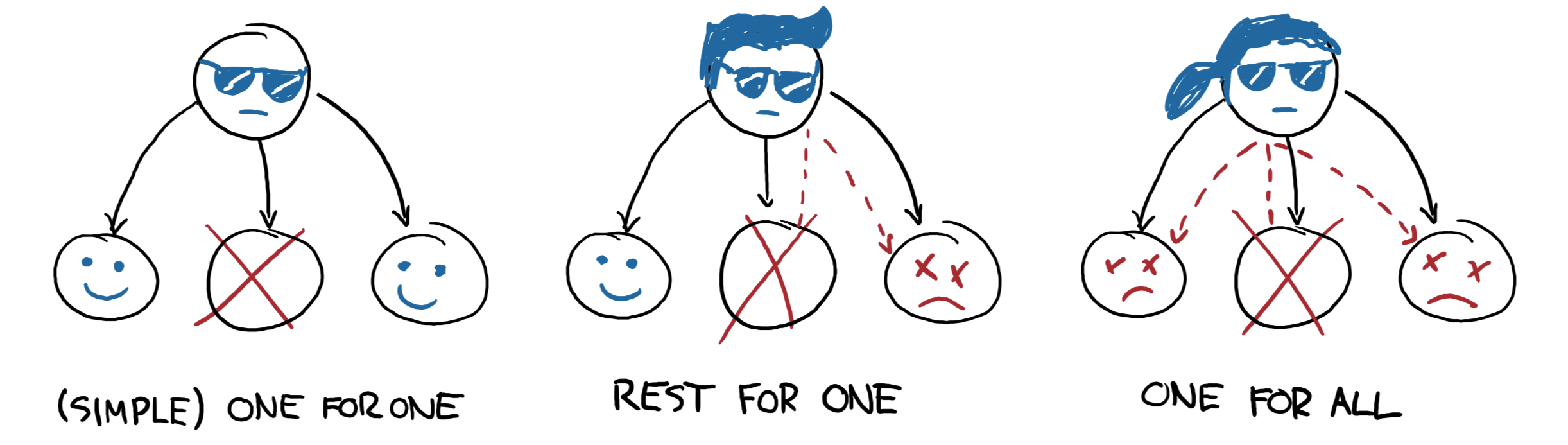
图 3:三种监管器类型
有三种策略类型
one_for_one,表示每个子进程都独立于其他子进程。如果一个子进程死亡,其他子进程不需要任何替换或修改。simple_one_for_one是在所有子进程类型相同(例如工作进程池)的情况下对one_for_one的专门化,速度更快,重量更轻。
rest_for_one对监管器子进程之间存在线性依赖关系进行编码。如果其中一个子进程死亡,则必须重启其后启动的所有子进程,但之前启动的子进程则不必重启。在进程C依赖于进程B,而B依赖于进程A的情况下,rest_for_one策略允许有效地编码其依赖关系结构。one_for_all是一种策略,如果任何子进程死亡,则所有子进程都必须重启。如果您希望所有子进程之间存在强依赖关系,则应使用这种类型的监管器;如果其中任何一个重启,其他子进程就没有简单的方法恢复,因此也应该重启它们。
这些策略实际上都是关于错误如何在监管器的子进程之间传播。接下来要考虑的是,在信号传播后,每个失败的进程本身应该如何由监管器处理。
| 重启策略 | 正常退出时 | 异常退出时 |
|---|---|---|
| permanent | restart | restart |
| transient | stay dead | restart |
| temporary | stay dead | stay dead |
这使您可以声明某些进程预计永远不会停止(permanent),某些进程预计会停止(transient),而某些进程预计会失败(temporary)。
我们可以设置的最后一个配置位是允许重启的频率。这通过两个参数 intensity 和 period 来完成,它们分别代表已发现多少次崩溃以及崩溃持续了多少秒。然后,我们可以指定监管器每小时只能容忍一次崩溃,或者如果需要,每秒可以容忍十几次崩溃。
这就是您声明监管器的方式
-module(myapp_sup).
-behaviour(supervisor).
%% API
-export([start_link/0]).
%% Supervisor callbacks
-export([init/1]).
-define(SERVER, ?MODULE).
start_link() ->
supervisor:start_link({local, ?SERVER}, ?MODULE, []).
init([]) ->
{ok, {{one_for_all, 1, 10}, [ % one failure per 10 seconds
#{id => internal_name, % mandatory
start => {mymod, function, [args]}. % mandatory
restart => permanent, % optional
shutdown => 5000, % optional
type => worker, % optional
modules => [mymod]} % optional
]}}.
您可以在其中一次定义任意数量的子进程(除了 simple_one_for_one,它期望一个描述模板)。您可以为子进程指定的其他参数包括 shutdown,它提供以毫秒为单位等待子进程正常终止的时间(或 brutal_kill 以立即终止它),以及关于进程是 worker 还是 supervisor 的定义。此 type 字段以及 modules 仅在使用发布进行实时代码升级时使用,后者通常可以忽略,并保留其默认值。
这就是全部所需内容。让我们看看如何在实践中应用它。
尝试自己的监管器
让我们尝试向应用程序添加一个带工作进程的监管器,运行本质上是地球上最繁重的Hello World。我们将为此构建一个完整的发布版。
$ rebar3 new release hello_world
===> Writing hello_world/apps/hello_world/src/hello_world_app.erl
===> Writing hello_world/apps/hello_world/src/hello_world_sup.erl
===> Writing hello_world/apps/hello_world/src/hello_world.app.src
===> Writing hello_world/rebar.config
===> Writing hello_world/config/sys.config
===> Writing hello_world/config/vm.args
===> Writing hello_world/.gitignore
===> Writing hello_world/LICENSE
===> Writing hello_world/README.md
$ cd hello_world
您应该识别发布结构,其中所有 OTP 应用程序都位于 apps/ 子目录中。
打开 hello_world_sup 模块,并确保它如下所示
%%%----------------------------------------------------------
%% @doc hello_world top level supervisor.
%% @end
%%%----------------------------------------------------------
-module(hello_world_sup).
-behaviour(supervisor).
-export([start_link/0]).
-export([init/1]).
-define(SERVER, ?MODULE).
start_link() ->
supervisor:start_link({local, ?SERVER}, ?MODULE, []).
init([]) ->
SupFlags = #{strategy => one_for_all,
intensity => 0,
period => 1},
ChildSpecs = [
#{id => main,
start => {hello_world_serv, start_link, []}}
],
{ok, {SupFlags, ChildSpecs}}.
这建立了一个子进程,该子进程将位于 hello_world_serv 模块中。这将是一个简单的 gen_server,它不执行任何操作,仅使用其 init 函数。
-module(hello_world_serv).
-export([start_link/0, init/1]).
start_link() ->
gen_server:start_link(?MODULE, [], []).
init([]) ->
%% Here we ignore what OTP asks of us and just do
%% however we please.
io:format("Hello, heavy world!~n"),
halt(0). % shut down the VM without error
此文件只启动一个 OTP 进程,输出 Hello, heavy world!,然后关闭整个虚拟机。
让我们构建一个发布版,看看会发生什么
$ rebar3 release
===> Verifying dependencies...
===> Compiling hello_world
===> Starting relx build process ...
===> Resolving OTP Applications from directories:
/Users/ferd/code/self/adoptingerlang/hello_world/_build/default/lib
/Users/ferd/code/self/adoptingerlang/hello_world/apps
/Users/ferd/bin/erls/21.1.3/lib
===> Resolved hello_world-0.1.0
===> Dev mode enabled, release will be symlinked
===> release successfully created!
现在我们可以启动它了。我们将使用 foreground 参数,这意味着我们将引导发布版以查看其所有输出,但在非交互模式下(没有 shell)执行此操作。
$ ./_build/default/rel/hello_world/bin/hello_world foreground
<debug output provided by wrappers bundled with Rebar3>
Hello, heavy world!
这里发生的事情是,工具在 /_build/default/rel/hello_world/bin/hello_world 中生成一个脚本。此脚本将一堆内容组合在一起,以确保您的发布版以所有正确的配置和环境值引导。
一切都从虚拟机启动开始,最终在 Erlang 本身中生成根进程。kernel OTP 应用程序引导,然后在配置数据中看到它必须启动 hello_world 应用程序。
这是通过调用 hello_world_app:start/2 完成的,后者又调用 hello_world_sup,后者启动 hello_world_serv 进程,该进程输出文本,然后向 VM 发出硬调用,指示其关闭。
这就是我们刚刚所做的。监管器只启动和重启进程;它们很简单,但它们的强大功能来自它们如何组合以及如何用于构建系统。
构建监管树
监管器最复杂的部分不是它们的声明,而是它们的组合。它们是一个简单的工具,可以完成复杂的任务。在本节中,我们将介绍监管树为何有效以及如何最好地构建它们以充分利用它们。
监管器有效的原因
每个人都听说过“你试过关机再开机吗?”作为一种通用的错误修复方法。它出奇地有效,而 Erlang 监管树正是基于这一原理运行的。当然,重启不能解决所有错误,但它可以解决很多错误。
重启之所以有效,是因为生产系统中遇到的 bug 的特性。要讨论这个问题,我们必须参考 Jim Gray 在 1985 年 创造的 Bohrbug 和 Heisenbug 两个术语。基本上,Bohrbug 是一种稳定、可观察且易于重复的 bug。它们往往比较容易理解。相比之下,Heisenbug 的行为不可靠,只在特定条件下才会出现,并且可能仅仅因为试图观察它们而隐藏起来。例如,并发 bug 因为使用调试器而导致系统中的每个操作都被序列化,从而臭名昭著地消失了。
Heisenbug 就是那些成千上万、百万、十亿甚至万亿次才会出现一次的讨厌的 bug。一旦你看到有人打印出几页代码,然后用一堆标记笔在上面大干一场,你就知道他们已经花了一段时间在解决一个 Heisenbug 了。
在定义了这些术语之后,让我们看看在生产环境中查找 bug 应该有多容易。
| 功能类型 | 可重复 | 瞬态 |
|---|---|---|
| 核心 | 简单 | 困难 |
| 次要 | 简单(经常被忽视) | 困难 |
如果你的系统核心功能中存在 Bohrbug,它们通常在到达生产环境之前就很容易被发现。由于它们是可重复的,并且经常位于关键路径上,你迟早会遇到它们,并在发布之前修复它们。
发生在次要、使用较少的功能中的 bug,则更像是碰运气的事情。每个人都承认,修复软件中所有 bug 是一场收益递减的艰苦战斗;随着时间的推移,消除所有细微的缺陷所花费的时间会成比例地增加。通常,这些次要功能会获得较少的关注,因为要么使用它们的客户较少,要么它们对客户满意度的影响较小。或者,它们可能只是被安排在稍后进行,而时间线的滑坡最终导致了它们的工作优先级降低。
Heisenbug 在开发环境中几乎不可能找到。像形式化证明、模型检查、穷举测试或属性测试等高级技术可能会增加发现其中一些或所有 Heisenbug 的可能性(取决于使用的方法),但坦率地说,除非手头的任务极其关键,否则我们很少有人使用这些方法。一个十亿分之一的问题需要大量的测试和验证才能发现,并且很有可能,如果你已经看到了它,你将无法仅仅靠运气再次生成它。
所以,让我们再看看之前关于 bug 类型的表格,但这次我们关注的是它们在生产环境中会发生的频率。
| 功能类型 | 可重复 | 瞬态 |
|---|---|---|
| 核心 | 绝不应该 | 一直 |
| 次要 | 相当频繁 | 一直 |
首先,核心功能中简单的可重复 bug 根本不应该进入生产环境。如果它们进入了,那么你基本上发布了一个有问题的产品,无论多少次重启或支持都无法帮助你的用户。这些问题需要修改代码,并且可能是产生这些 bug 的组织内部一些根深蒂固的问题的结果。
次要功能中的可重复 bug 经常会进入生产环境。这通常是由于没有时间或没有充分测试它们导致的,但也极有可能,在进行部分重构时,次要功能往往会被遗忘,或者设计它们的人员没有充分考虑该功能是否与系统的其余部分和谐地融合。
另一方面,瞬态 bug 将会无处不在。创造这些术语的 Jim Gray 报告说,在特定客户站点记录的 132 个 bug 中,只有一个是 Bohrbug。在生产环境中遇到的错误中,有 131/132 属于 Heisenbug。它们很难捕捉,如果它们确实是统计学上的 bug,可能几百万次才会出现一次,那么只要系统负载稍微增加,它们就会一直触发;一个十亿分之一的 bug 会在一个每秒处理 100,000 个请求的系统中每 3 小时出现一次,而一个百万分之一的 bug 在这样的系统中也可能每 10 秒出现一次,但它们的发生在测试中仍然是罕见的。
有很多 bug,如果处理不当,就会导致很多故障。让我们重新整理一下表格,但现在我们要考虑重启是否能够处理这些故障。
| 功能类型 | 可重复 | 瞬态 |
|---|---|---|
| 核心 | 否 | 是 |
| 次要 | 视情况而定 | 是 |
对于核心功能中的可重复 bug,重启是无效的。对于不太常用的代码路径中的可重复 bug,则视情况而定;如果该功能对极少数用户非常重要,那么重启不会有什么作用。如果它是一个每个人都使用的次要功能,但他们不太关心,那么重启或完全忽略故障都可以很好地工作。
但是,对于瞬态 bug,重启非常有效,而且它们往往是你在线上遇到的 bug 的大多数。因为它们很难重现,它们的出现通常依赖于非常特定的环境或系统中状态位的交错,并且它们的出现往往只占所有操作的一小部分,所以重启往往会使它们完全消失。
监督器允许你系统中受到此类 bug 影响的部分回滚到已知的稳定状态。一旦你回滚到该状态,再次尝试不太可能遇到导致第一个 bug 的相同奇怪上下文。就这样,原本可能是一场灾难的事情,变成了系统的一个小故障,用户很快就会习惯它。
关乎保障
Erlang 监督器及其监督树的一个非常重要的部分是它们的启动阶段是同步的。每个启动的 OTP 进程都有一个时期可以做自己的事情,从而阻止其兄弟姐妹和堂兄弟姐妹的整个启动序列。如果进程在此期间死亡,它将被再次重试,并且会一直重试,直到它成功或失败次数过多。
这就是人们经常犯的一个错误。在监督器重启崩溃的子进程之前,没有退避或冷却时间。当人们编写基于网络的应用程序并尝试在此初始化阶段建立连接时,如果远程服务已关闭,则应用程序在经过太多无结果的重启后将无法启动。然后系统可能会关闭。
许多 Erlang 开发人员最终会赞成一个具有冷却时间的监督器。这种观点是错误的,原因很简单:这一切都关乎保障。
重启一个进程是为了将其恢复到一个稳定、已知的状态。从那里,可以重试。当初始化不稳定时,监督的作用很小。初始化后的进程应该无论发生什么都保持稳定。这样,当它的兄弟姐妹和堂兄弟姐妹稍后启动时,它们可以在完全知道之前启动的系统其余部分是健康的的情况下启动。
如果你没有提供这种稳定状态,或者如果你要异步启动整个系统,那么你从这种结构中获得的好处,与循环中的 try ... catch 几乎没有区别。
被监督的进程在其初始化阶段提供保障,而不是尽力而为。这意味着,当你为数据库或服务编写客户端时,你不应该需要在初始化阶段建立连接,除非你准备好声明它无论发生什么都将始终可用。
例如,如果你知道数据库在同一主机上,并且应该在你 Erlang 系统之前启动,那么你可以在初始化期间强制建立连接。然后重启应该可以工作。如果出现一些无法理解和预料之外的事情破坏了这些保障,那么节点最终会崩溃,这是可取的:启动系统的先决条件没有满足。这是一个失败的系统级断言。
另一方面,如果你的数据库位于远程主机上,你应该预期连接会失败。在这种情况下,你可以在客户端进程中做出的唯一保证是你的客户端能够处理请求,但不能保证它会与数据库通信。例如,在网络断开期间,它可能会在所有调用中返回 {error, not_connected}。
然后可以使用你认为最佳的任何冷却或退避策略来重新连接到数据库,而不会影响系统的稳定性。它可以在初始化阶段作为优化尝试,但如果出现任何断开连接,进程应该能够稍后重新连接。
如果你预计外部服务会出现故障,不要将其存在作为你系统的保证。我们在这里处理的是现实世界,外部依赖项的故障始终是一种可能性。
当然,如果调用客户端的库和进程没有期望在没有数据库的情况下工作,那么它们就会出错。这在不同的问题空间中是一个完全不同的问题,但并非总是无法解决。例如,假设客户端是针对运维人员的统计服务,那么调用该客户端的代码很可能忽略错误,而不会对整个系统产生不利影响。在其他情况下,可以在客户端前面添加一个事件队列,以避免在事情变得糟糕时丢失状态。
初始化和监督方法的区别在于,客户端的调用者决定他们可以容忍多少故障,而不是客户端本身。在设计容错系统时,这是一个非常重要的区别。是的,监督器是关于重启的,但它们应该是在重启到一个稳定已知状态。
不断增长的树
当你构建 Erlang 程序时,你认为脆弱且应该允许失败的所有内容都必须移到层次结构的更深处,而稳定且关键的内容需要可靠则需要放在更高级别。监督结构允许对部分故障和故障传播进行编码,因此我们必须正确考虑所有这些事情。让我们再看看我们示例的监督树。
如果 DB 子树中的一个工作进程死亡,并且 DB 是一个使用 one_for_one 策略的监督器,那么我们就编码了每个工作进程可以独立于彼此失败。另一方面,如果 event_sup 使用 rest_for_one 策略,那么我们就编码到我们的系统中,如果事件监听器死亡,则处理订阅的工作进程必须重启;我们说存在直接依赖关系。
隐式地,还有一个说法是,只要事件处理子树在某个时刻成功启动,它就不会直接受到数据库的影响。
这个监督树可以像一个调度表和系统故障图一样阅读。除非域特定工作进程可用,否则 HTTP 服务器不会启动,并且 HTTP 处理程序失败不会做任何可能危及数据库缓存的事情。当然,如果 HTTP 处理程序依赖于域工作进程,而域工作进程又依赖于缓存的 ETS 表,并且该表消失了,那么所有这些进程可能会一起死亡。
这里真正有趣的是,我们可以一目了然地知道即使是未知的故障也可能如何影响我们的系统。我不需要知道数据库工作进程为什么会失败,无论是由于断开连接、数据库死亡还是协议实现中的 bug;我知道无论如何,这都应该保留缓存,并可能让我进行陈旧读取,直到数据库子树再次可用。
这就是子进程的重启策略与监督器接受的故障频率发挥作用的地方。如果所有工作进程及其监督器都被标记为 permanent,那么频繁崩溃可能会导致整个节点宕机。但是,你可以做一个小技巧
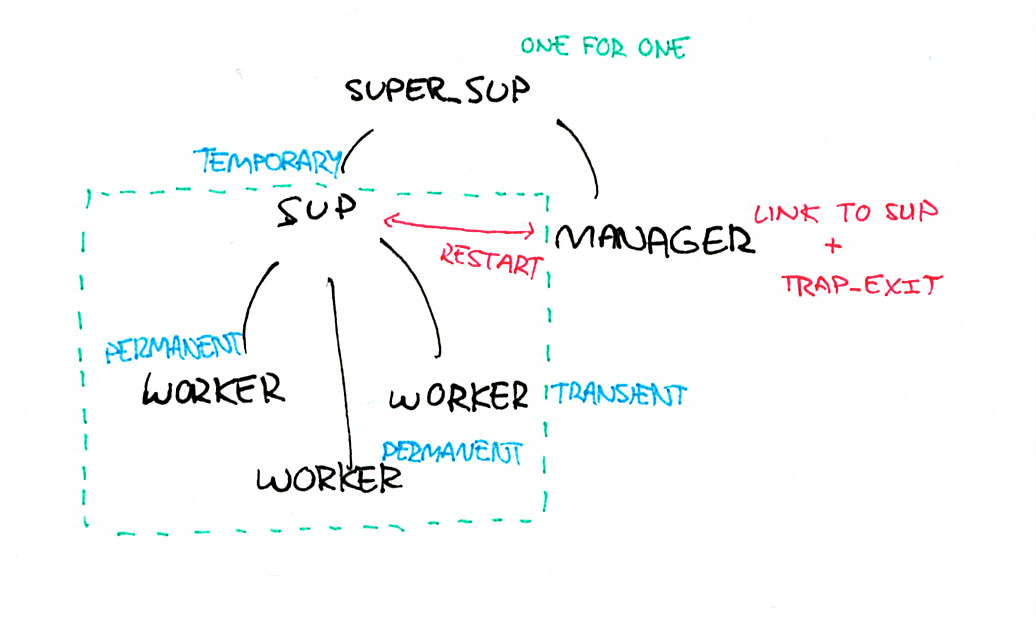
图 4: 管理器工作进程模式
- 将工作进程标记为
permanent或transient,以便如果它们失败则会被重启 - 将工作进程的直接上级主管(方框内)标记为
temporary,这样如果它失败,就会放弃并不会重新启动。 - 在其上添加一个新的主管(这个主管可以使用任何你想要的策略),但将其设置为
one_for_one。 - 在新主管下添加一个新的进程(
temporary主管的兄弟进程)。让这个进程与旧主管链接。这就是管理器。
临时主管可以用来容忍可接受的重启频率。例如,它可以表示工作进程每两分钟死一次是正常的。但是,如果我们超过了这个阈值,说明发生了不好的事情,我们希望停止重试,而不会冒使节点不稳定的风险。主管会关闭,并且由于它是临时的,所以超级主管(方框的上方)将只是停留在那里什么也不做。
然后,管理器可以查看sup主管是存活还是死亡,并在重启它时应用任何它想要的策略:使用指数退避,等待断路器恢复,等待外部服务注册表表示依赖的服务再次健康,或请求用户输入下一步操作。然后,管理器可以请求它自己的父主管重新启动临时主管,后者将随后重新启动它自己的工作进程。
这是Erlang中为数不多的设计模式之一。因为智能系统会犯愚蠢的错误,所以我们希望使主管尽可能简单和可预测。管理器是我们为主管嫁接了一个大脑,并做出更高级的决策。这让我们能够将瞬态错误的策略与更重大或持续性故障的策略分开,这些故障不能仅仅通过重启来解决。
注意
这个模式可以根据你的需要进行调整。例如,作者使用了以下两种变体来管理重启
- 多个监控树嵌套在一起,每个树代表一个物理设备的工作进程池。每个物理设备都允许发生故障、离线或断电。管理进程会定期将正在运行的子树与一个位于异地的配置服务进行比较。然后,它会启动所有缺失的子树,并关闭所有不再存在的子树。这使得管理器能够处理运行时配置同步,同时还能处理棘手的硬件故障场景的重启。
- 管理器什么也不做。但是,Erlang发行版附带了一个脚本,操作员可以调用它。该脚本向管理器发送一条消息,要求它重新启动缺失的子树。使用这种变体是因为子树只在极少数情况下才会死亡(整个区域的存储出现故障),而不想杀死系统的其余部分,但在恢复后,操作员可以通过这种方式重新启用流量。
虽然很难在一个通用的主管中烘焙这种功能,但管理器可以轻松地提供这种定制解决方案所需的灵活性。
我们建议你做的一项练习是,获取你的系统,然后在白板上绘制它的监控树。遍历所有工作进程和主管,并提出以下问题
- 如果它死了可以吗?
- 是否应该与之一起关闭其他进程?
- 这个进程是否依赖于其他一些在它重启后会变得奇怪的东西?
- 对于这个主管来说,多少次崩溃太多了?
- 如果系统的这部分完全坏了,系统其余部分应该继续工作还是应该放弃?
与你的团队讨论这些问题。重新排列主管,调整策略和策略。添加或删除监控层,在某些情况下,添加管理器。
定期重复此练习,并最终进行一些混沌工程,在运行的节点上杀死Erlang进程,以查看它是否按你预期的方式运行和恢复(当然,你也可以对整个节点进行混沌工程,这更常见)。最终你会得到一段容错代码。你还会建立一个团队,他们对系统中内置的故障语义有深刻的理解,并对事物在不可避免地发生故障时如何分解有一个良好的心理模型。这价值连城。